Intro
In this overview post we show how Reinforcement Learning (RL) can be applied to testing games. We do this by means of several papers and use cases. We show how you can detect errors in level design and game breaking bugs. It may be helpful to read our introduction to RL first if you are unfamiliar with the concept.
Testing levels
The SEED research group, part of EA, published a number of papers last year in which RL is applied to detect level issues. This includes places where a player is not allowed to go, cannot go or gets stuck. Traditionally, levels are tested by human testers. The motivation for having this done automatically is severalfold:
• Human testers are expensive
• It is monotonous and boring work
• Human testers can better spend their time testing mechanics and gameplay.
Bots do this without complaint and very efficiently. In this chapter we discuss a methodology proposed in two papers that we discuss below.
Augmenting automated game testing with deep reinforcement learning
This paper lays the foundation for using an RL agent to make automated testing more flexible. In a development process, levels change continuously. This sometimes makes using scripts difficult. Agents who have learned to navigate can be deployed to remain useful in changing environments.
Method
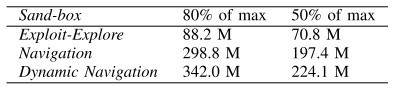
The authors propose four different environments corresponding to some challenges:
• Exploit: In this environment, a collision mesh is missing on a section of wall. The agent’s challenge is to find this exploit.
• Stuck Player: An environment in which certain trigger volumes prevent the player from moving. This simulates geometry that the player can get stuck in.
• Navigation: An environment in which the agent is tasked with navigating from point A to point B.
• Dynamic Navigation: An environment similar to Navigation, but with moving platforms.
The observation is made up of:
• Agent info (location, rotation, velocity, state)
• Target info (location)
• Vision array: 12 ray casts in as many directions to observe the environment
The authors compare different algorithms (PPO, SAC, TD3 and DDPG).

Environment for Exploit and Stuck Player

Environment for Navigation and Dynamic Navigation
Results
The four environments are evaluated using: heat maps and visualizations. The agent always starts in the same place. He receives a reward based on achieving goals. A goal is a place in the level. When an agent achieves a goal he obtains a new goal.
Exploit

Comparing the heatmaps of the scripted player (a) and the fully trained RL agent (d) we see that the RL agent has clearly found the exploit for the route to the bottom right targets.
Stuck Player

The orange blocks represent the locations where an agent was at the end of a run. The purple squares indicate the locations of the volumes where agent control is disabled. With the naked eye we can see that this corresponds to concentrations of end positions. A cluster algorithm can automatically detect these.
Navigation and Dynamic Navigation
The white dots in the images on the right correspond to the different goals an agent is given. In the right image we see 2 targets on the left that we do not find in the left image. These goals are more difficult to achieve and therefore require more training.

Difficulty Level
Improving playtesting coverage via curiosity driven reinforcement learning agents
The DRL model
Bearing in mind the RL loop, we define the observation output and reward signal of the agents here. It is important that the bots interact with the application just like real players. Therefore, they do not use a navigation graph or navmesh. A Deep Neural Network translates the observation into the right action. The observation is made up of various orientation features (position, velocity, rotation), player states (is climbing, on ground, jump cool-down time) and a field of view (12 raycasts that represent a distance to collision and a semantic opinion about the surface).
The authors also discuss a variation in which an additional first-person view is provided. Possible actions correspond to input actions the player can take. There are 3 continuous actions (forward/backward, turn left/turn right and step left/step right) and 1 discrete action (jump). The reward signal determines the agent’s behavior. The desired behavior in this case is an agent that will explore the folder. So it doesn’t matter how well the agent plays the game, but it does matter how many places in the map the agent goes. To achieve this, the agent receives a reward when he enters undiscovered territory. The chosen training algorithm is Proximal Policy Optimization (PPO). A popular algorithm due to its robustness and also implemented in Unity ml agents.
Results
In the video below the authors show their results:
Opinion about both papers
The implementation of the agents in both cases seems very intuitive (inputs and outputs). The coverage of the level is very large and the agents are able to reach places that require a certain skill. The importance of a good visualization of what the agent does becomes clear here. The different visualizations make it clear how an agent reaches a certain place and where there are possible errors in the level. Agents can be a valuable addition to existing scripts to perform these simple tasks. The PPO algorithm appears to be an excellent choice for this.
Searching for bugs in the application
The above method detects errors in the level design, but cannot be used to detect errors in the application itself. Below we show how RL can also be used for this. The authors propose the Wuji framework to test games on-the-fly. They focus on detecting crashes and the application getting stuck. Other types of errors (logical, balance or player experience) are more difficult to be recognized by an algorithm.
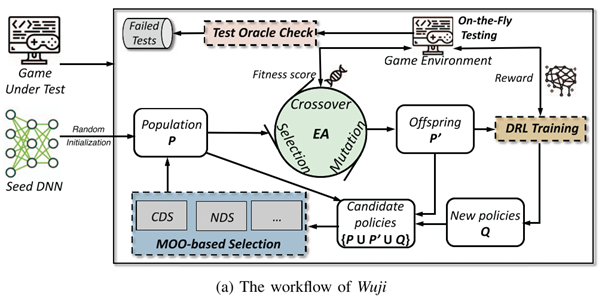
The Wuji framework
Test environment
The authors collaborated with the company NetEase. This way they had access to real data and could work closely with game developers. Wuji was tested on 2 online combat games: A Chinese Ghost story and Treacherous Water Online.
Architecture
The Wuji framework is a combination of different AI techniques. The central idea is to generate policies that explore more game states where bugs may occur. A policy is the way an agent will interact with the game. An agent is implemented with a Deep Neural Network with an advantage actor critical architecture (which is also the basis of PPO). The agent is trained to score as high as possible in the game.
In a mouthful of words, Wuji uses a genetic multi-objective optimization algorithm to test as many game states as possible. A population of DNN agents is trained each iteration and each agent is evaluated based on 2 objectives: game score and visited game states. The crossover within the population takes place on the basis of these evaluations. After this, the new species are trained so that the population is ready for the next iteration. The chance that an error will be found during this process is considerably higher since the focus is on exploration (different playing styles) and exploitation (valid playing styles that actually play the game) at the same time.
To detect the errors, 2 types of oracles are implemented. The first oracle monitors whether the application is still running. This oracle is used to detect crashes. The second oracle monitors the change of the game state. This makes it possible to detect whether the application is stuck.
Results
A test environment was set up with the help of the developers of both games. This is how errors were introduced into the game. All errors were found by Wuji. Even more: 3 bugs were found that were previously unknown.
Opinion
For simple games, Wuji is probably overkill. For more complex games, such as those used in the experiments, Wuji seems like a method that will perform. However, finding errors in the game logic is not possible here. Implementing an oracle that detects such errors is the biggest challenge here.
Conclusion
Reinforcement Learning is taking major steps forward in the gaming world. 2 years ago there was still doubt about how accessible the technology was to get started with yourself. The games presented here are not as complex as Starcraft, but still offer a strong challenge. It is remarkable that RL agents can also be implemented fairly intuitively for this purpose. If you work in Unity, you should definitely consider installing the ml-agents plugin and getting started with PPO.