In this blog post we give a brief introduction to Reinforcement Learning (RL) and look at a number of applications within the gaming world. The goal is to stimulate your ideas, and also to demonstrate that you don’t have to be an AI expert to get started with these technologies. We look forward to questions or ideas arising from this blog post and are happy to take all input into account in preparation for the planned workshops.
Reinforcement learning
RL is an AI technique based on concepts from behavioral psychology. Just as we can teach desired behavior to children through… punishment and reward, we can also do this for virtual entities, also called agents in the jargon. The big advantage of RL is that we don’t necessarily need a lot of data to train a model, a requirement that most other Machine Learning techniques have. So what do we need? A learning environment, typically called an environment, and time to let the agent explore within it. We can schematically represent a typical RL learning process as follows:
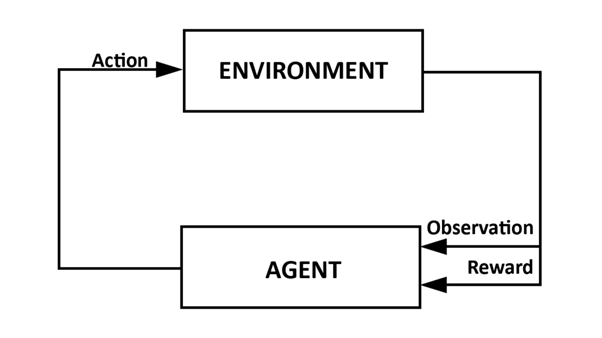
Overview of the RL learning process.
The learning process in which the agent learns a new behavior is typically called training and is iterative. In the first step, the agent observes the state of the environment each time. The observation tells the officer more about himself and the environment. This can range from its location, distance to a certain object, time… This information does not have to be numerical: pixel data can also be used. Based on that observation, the agent then chooses an action and carries it out. He observes the new environment, and also receives a reward. An agent’s behavior, also called policy, actually involves a mapping from observations to actions.
The value function and Artificial Neural Networks
Which action an agent takes depends on the value judgment that followed each action and is based on his observation of the learning environment. This value judgment is given by a value function, and reflects the expected reward the agent will receive if he takes this action. This prediction is adjusted throughout the learning process based on the experiences gained. Finding the right policy is actually the same as finding a value function that maximizes future rewards. In the most recent methods, the value function is implemented using an Artificial Neural Network (ANN), a term you have probably heard mentioned many times in conversations around AI.
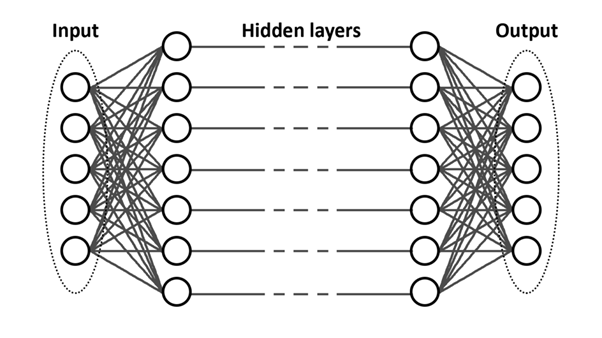
A schematic representation of an Artificial Neural Network. The values of the input nodes (left) are sent through the network until we have calculated the calculated output (right). An ANN consists of several layers of nodes that are interconnected. The first layer is the input to the network, and corresponds to the agent’s observation. The last layer corresponds to the actions the agent can take. All layers in between are operations that determine which action is optimal based on observation. Training an agent comes down to fine-tuning the parameters of the Neural Network. This fine-tuning is done by comparing the predicted reward with the reward obtained in the learning process.
Reward function
The rewards directly determine the behavior that the agent will teach himself. Finding the right reward mechanisms or reward functions becomes more challenging as the complexity of the learning environment increases. For example, in the simple game Pong, it is easy to come up with a reward function: -1 when the agent misses the ball, and +1 when the agent scores a point. As soon as the complexity increases it is clear that we are faced with a more difficult thinking exercise. What makes it even more difficult is that in games the rewards often only come after taking a whole series of actions that are linked together. With the help of imitation learning we can significantly accelerate the agent’s learning process and make it easier to devise reward functions. By recording desired exemplary behavior, we can reward agents based on how their behavior deviates from these recordings. These recordings must be made manually.
Applications in games
The applications of RL in games vary and in theory the possibilities are endless. From the literature, we have long seen an interest in applying RL in games, because games offer scenarios that are simpler than the real world, but challenging enough to prove that the AI algorithms work.
The state-of-the-art around RL is currently being developed by Google DeepMind. This team is developing an agent who can play Starcraft2 better than all the pros. Their agent, named AlphaStar, was already better than 99.8% of human Starcraft2 gamers in October 2019. The goal of the Google Deepmind team is not only to create a superbot, but also (and especially) to further explore and expand the domain of RL. It is this knowledge that we can reuse for other applications.
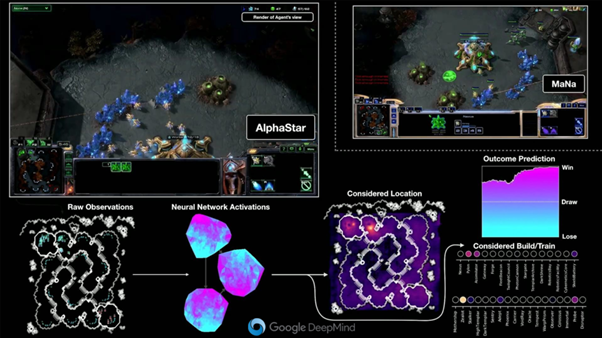
A fraction of AlphaStar’s brain. At the bottom left we see the input (in this case an image) for the neural network, then we see the zones that the agent focuses on to determine a new construction location. AlphaStar is made up of several ANNs, each responsible for an aspect of the decision process. RL research is not limited to playing real-time strategy games. Agents who completed successful play sessions have also been trained for first-person shooters, text adventures, team sports, racing, arcade and open-world games. These successes point to the possibilities of using RL within the context of games. These agents can be used in various areas. We give some examples. An agent that can approximate human gaming behavior could be used to perform gameplay balancing tests. Agents can also provide us with interesting insights and collect data during our production process when we create new content. Just think of an agent exploring a new map or level, an agent fighting a new enemy, an agent trying out a new weapon or trying to solve a puzzle…
Let's get to work!
Decision levels
We distinguish between 3 levels at which agents, just like players, make decisions: strategic, tactical and instant. At the lowest level we see the decisions about what input we are going to give in the game. This is purely about the use of controllers. At a higher level, decisions are more about small tasks: opening a door, tactical navigation, solving a puzzle. One level higher are the decisions about larger strategies: resource management, overall plan of action to win a game or army compositions. To summarize: a strategic decision consists of several tactical decisions, which in turn consist of instant decisions.
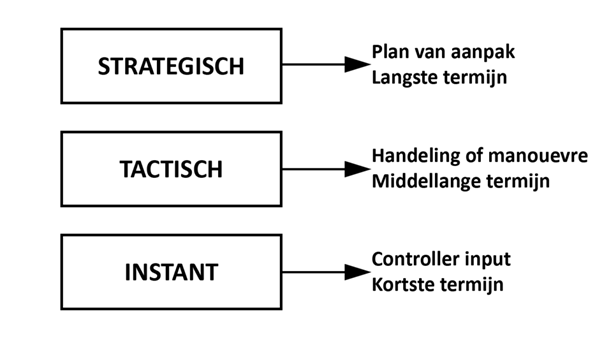
De drie verschillende beslissingsniveaus voor spelers/agents.
Het is eenvoudiger om een agent te trainen die beslissingen neemt op 1 bepaald niveau dan een agent die op alle niveaus tegelijk handelt. Het is dus goed om na te denken welke taken geleerd moeten worden door de agent, en welke door een ander systeem (pathfinding, animatie, tree-search…) kunnen worden overgenomen. Dit heeft ook invloed op de observatie. Een agent die redeneert over de logische stappen om een deur te openen, heeft minder nood aan observaties die te maken hebben met vijanden of score. (Tenzij deze een trigger vormen om de deur te openen natuurlijk.)
Implementation
Fortunately, it is not necessary to start from scratch with an implementation of all RL algorithms. There are numerous free (open-source) libraries available. The most famous are Tensorflow, Keras, Pytorch and OpenAI. They have a Python front-end that makes it easy to link your own application and put together neural networks. If you work in Unity3D you can opt to use Unity ML agents, an open-source plugin that uses Tensorflow and offers the best RL algorithms ready for implementation. Training agents naturally requires a simulation environment in which they have the opportunity to learn. To ensure that agent training runs optimally, certain aspects of this environment are important: speed, stability, determinism and observations. Speed is trivial, the faster your simulation can run, the faster agents can train. Stability and determinism are partly related. In accelerated simulations in which the agents train, it is important that things such as physics continue to work correctly. Speed has its limit where the simulation starts to show errors due to loss of precision, and thus becomes unstable. Finally, an agent must also be able to easily make an observation of the environment. As mentioned, this can be done via pixel data, but it is often easier to choose what the agent observes. Through ray-casts, locations and information about the agent, it is easier to maintain control over what the agent is paying attention to.
Useful and interesting links
Unity ml-agents: https://github.com/Unity-Technologies/ml-agents
RL penguins in Unity ml-agents: https://www.immersivelimit.com/tutorials/reinforcement-learning-penguins-part-1-unity-ml-agents
Het AlphaStar project van Google Deepmind: https://deepmind.com/blog/article/alphastar-mastering-real-time-strategy-game-starcraft-ii
Getting started with RL and Tensorflow: https://www.tensorflow.org/agents/tutorials/0_intro_rl
Spinning up in deep RL with OpenAI: https://openai.com/blog/spinning-up-in-deep-rl/
Getting started with RL and PyTorch: https://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html