Audio is an essential element to the success of any game. It provides an immersive experience that can make the difference between the player enjoying a game or becoming frustrated and giving up.
Delayed, missing or incorrect sound effects can seriously affect the immersion of the game. Additionally, inconsistent, or sudden changes in volume of the background music can break immersion.
With this use case we want to investigate what the impact of AI for audio in games can be, and if problems such as error detection in sound effects and music can be addressed.
This may or may not bother players while playing, however, the right sound effects or background music can set the atmosphere while playing a game. Additionally, audio is an important element in determining what is happening in the game at any given moment. This can be illustrated by moments such as enemies sneaking up on you from the side, giving them the advantage to attack.
Unfortunately, audio issues still exist in games. They can be caused by several factors, including code changes, assets that are not properly optimized, or simply the way the game is played. We refer to these as bugs.
Actively detecting audio bugs requires quite some time. Furthermore, these are sometimes overlooked because game testers give a lower priority to audio. For example, people sometimes test without their headphones or with the volume set to 0, because detecting graphical and functional bugs involves a lot of repetition, which means that sound effects are also played ad nauseum.
In this use case, we explore ways to automatically detect audio bugs during development. This can help you identify and resolve them before they cause problems for the players. However, we’ll ignore the more nuanced challenges with audio, as detecting technical things like room temperature are too niche to delve into further.
Audio bugs: Types of Problems with Audio in Games
Below is a summary of the types of problems one may encounter with audio during the development phase of games.
Overrun Voices
When several voices play at the same time this can be very disruptive and overwhelm the player. Ideally, one character should speak at a time, rather than speaking over themselves with several voice overs (VO) playing on top of each other.
Reverberation
Reverb, is a sound phenomenon that arises from repeated reflection of sound. It is also possible to add this digitally as an effect to the audio, so playing with this value can make it seem as if you are in different rooms.
If the reverberation of sound effects is not properly matched to the game’s environment, immersion will be greatly affected. When in a game you forge a sword in a small hut but the sound effects sound like you are hitting a gong in a large hall, this immediately raises some questions.
Surface mismatch
Different surfaces each make their own specific sound when walking over them. Just think of the sound of your footsteps on an iron staircase, a concrete floor or on a hard parquet. In a game it can sometimes happen that a certain surface or area does not make any sound while you would expect it to, this is called occlusion.
Non-Spatialized Effects
When you hear a bird chirping in-game, the sound source is spatialized to come from a certain direction. For examle you hear the same bird whistling loudly in both ears, but it is 100 meters away in a tree, then you have a problem with a non-spatialized effect.
Engine Specific Bugs
This is a general category, but nevertheless also causes problems with audio. An example of an engine bug could be that sound effects cannot be loaded, are played with a delay, or the audio stuttering during playback.
Voice Overs
This is less common in production, but during development the transcripts of the VOs can change, the voice can be of the wrong gender, or the VOs are accidentally swapped or reused. So, solving this requires listening to or playing the game again and again at the end of each iteration or when significant changes are made.
Purpose of Research
There are numerous types of audio bugs that can occur in games. Problems with volume is something that can be automated without the use of AI. To gain added value from an AI solution that is relevant to a broad audience, the right focus is to detect sound effects, with or without overlapping background music.
The aim of our research is therefore to investigate to what extent it is possible to detect sound effects. We then also want to keep track of the detected audio fragments with exact timestamps to generate a visual overview of the audio that took place in-game. In addition to bug detection, this approach is also suitable for other subjects, such as summarizing the highlights of a recording, or providing it with automatic tags based on the audio recognized in the video.
With this approach we can therefore detect three types of audio bugs: missing, delayed and wrong audio.
Approach
We have mapped out the following phases:
– Creating a small data set that is representative of the sound effects that can occur in games.
– Training an AI with this dataset.
– Testing the AI and measuring its performance on alternative similar sound effects within the same category.
Creating a Dataset

Initially, we created a small dataset with different audio effects spread across fifteen categories. This ranges from the sound of swords to UI clicks, to glass breaking, to beeping, scratching, opening, closing sci-fi doors and more. Foley is also included in this dataset, which is a collective name for everyday sounds that are needed to perfect the atmosphere and games or film. Each category varies from 40 to more than 100 samples of sound clips. Below you can see an overview of some sounds from the dataset with their waveform. [DR1]
These waveforms provide information about their amplitude (y-axis) over time (x-axis). It is more informative to display the information in the form of a mel spectrogram. With a mel spectrogram, the amplitude that was previously on the vertical axis is now displayed in the color dimension in decibels. The vertical axis now shows the number of Hertz, with low tones shown at the bottom of the spectrogram and high tones at the top. [DR2]
So, we converted our audio files to images. The overview of our dataset now looks like this: [DR3]
Some comments about the dataset. You can see that there is a connection between sound effects from the same category. This example is just a small sample of the hundreds of audio files in the dataset. Some sounds from the same category vary widely, such as the sword being waved in the air, being holstered, or hitting another sword. The ‘door’ category even consists solely of widely varying sci-fi effects for doors in futuristic games, to test the broad applicability of the AI approach. You may also be wondering why the glass is the lowest sound in the data set: these two audio files represent tiny shards of glass being shifted, not the same sound you hear when you tip a wine bottle into the glass container.
Training an AI
Instead of a dataset of audio files, we now have a dataset that has been transformed into images. So, we’re going to use the same type of neural network that can be used to distinguish dogs from cats, make self-driving cars detect objects, recognize faces, or detect visual bugs in games. This type of neural network is called a Convolutional Neural Network, or CNN for short. CNNs are often the go-to AI solution for anything that requires processing visual input. If you are interested in exactly how this works, be sure to check out the workshop ‘Computer vision in Unity’.
We train the AI on six different of the fifteen categories with sound effects as a first experiment. This only takes a few seconds, and the reported accuracy is 96%. We then use a confusion matrix to measure the AI’s ability to distinguish audio per category. [DR4]
On the vertical axis of the confusion matrix, you will see the effective labels. The horizontal axis shows what the AI’s prediction was. In the first column you can see that 76 of the ‘polystyrene’ predictions were correct, and that once the sound of glass was incorrectly confused with polystyrene, which is understandable. The AI had the most trouble with the “glass” prediction, incorrectly labeling the sound of a sword twice and three times that of polystyrene as glass. Apart from this, the results are quite impressive, the margin of error here is very low (only 8 errors in total out of hundreds of predictions) and we can therefore be fairly certain that the AI is able to classify sound effects correctly.
This knowledge can then also be extrapolated to new sound effects that belonged to the same category. For example, if we train the AI on different samples of broken or breaking glass, it does not need to be completely retrained to recognize a new variation of breaking glass.
The added value of this is that factors such as compression or other slight distortions of the audio do not affect the detection capabilities of the AI. Procedurally generated audio files can also still be linked to their correct category in this way.
Next Steps
It’s clear that using a CNN for audio is the right approach, and it works well even with very different audio. The logical next step is to work with a much larger data set.
The database we use for this is AudioSet, a gigantic audio collection from Google that consists of 527 categories of different sounds from 10-second audio clips from more than 2 million videos combined, which amounts to 5800 hours of audio. [DR5]
We will delve deeper into the ontology of the dataset: [DR6]
This is just a brief overview, for example for the horse category you have 4 different categories, consisting of blowing, snorting, neighing and galloping. So, we can annotate audio from all kinds of sources at a very detailed level.
Obviously, this dataset is not necessarily representative of every type of game, as sound effects are unique to most games and also specific to the genre being played. An FPS shooter is not going to have the same sound effects as a cartoony platform game. We have already shown that it is perfectly possible to train an AI for your own game on a smaller scale.
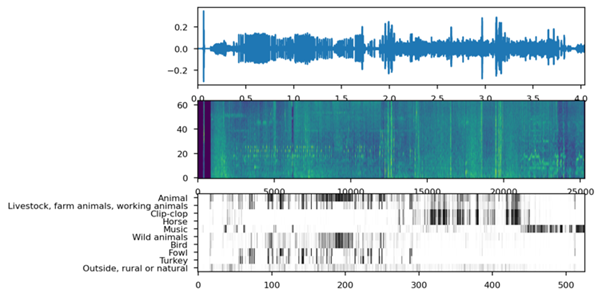
In addition to annotating individual audio clips, we have gone a step further with our new AI. Particularly for longer or continuous sound fragments, it is important to detect individual events. So, we will distill different and possibly even overlapping audio classes by keeping timestamps of detected audio fragments. This way we can generate an overview of the entire audio file with the 5 most common categories.
To verify how well this dataset works, we used it on different types of games with varying genres. The result for each type of game can be seen here: [DR7]
As you can see, it is clear at a glance what to expect in terms of audio for each game.
If you are looking for a specific audio event in a long recording, you no longer have to watch it from A-Z to make sure you haven’t accidentally skipped a single moment.
This information can be used to detect missing, incorrect or delayed audio effects. It is also perfectly possible to interpret whether the correct audio is being played. For certain actions you can set a trigger with a certain label. If the expected audio is not played within x number of milliseconds, it would not hurt to report this.
Conclusion
The aim of our research was to investigate to what extent it is possible to detect sound effects. We can hereby confirm that we are indeed able to detect sound effects in games with high accuracy with AI, in fact, we can generate nice overviews for long recordings in a very efficient way.
We can conclude that using AI to detect audio events is very successful. With the right data at hand, it is quite easy to train an AI, even without special system requirements. To troubleshoot specific audio issues, this can help during the development process to detect incorrect, missing and delayed sound effects.
This technology may also be interesting for other use cases, where a compilation is automatically created from unannotated video fragments. If you want to summarize and rewatch all the explosions from a shooting game from a one-hour gameplay video, this is the go-to solution.
A potentially interesting follow-up study to distinguish challenges with audio or specific more technical aspects of audio with an AI solution has a great chance of delivering valuable results.
Code and Results
Code and results
We have two notebooks that can help you get started with the technology discussed. You can find the results in these notebooks.
Training an AI on your own audio dataset: Google Colab
Using a pre-trained AI on AudioSet to summarize recordings: Google Colab