Good news for people without programming experience. You can now put together a game without even typing a letter of code. We can now indeed automatically generate code with language models. This is done using simple commands, or the model simply supplements existing code. And for beginners: a language model can check your code for syntax errors and also optimize them automatically. Even for more experienced programmers, there is sometimes still rehearsal or research work. Especially when juggling between different languages. In this blog post we see how programming is now easier than ever before.
Language models
So, how exactly does this work? Just as we can translate between English and Dutch with AI, it also appears to be possible to convert English into code. Or from bad code to good code! The name of such an AI that solves language problems is a language model. We have already seen examples of this in our blog post about conversational AI.
The nice thing about this is that there are many interesting possibilities to use it.
GPT-3
GPT-3 may need no introduction. This model is known for its ability to write highly credible text and articles. Below is an example from May 2020:


Read more: https://t.co/W1PVlsHdu4
Nice background information: GPT-3 has absorbed 45TB (without compression) of text from various data sets. This enormous task costed between $4 million and $12 million. To put this into perspective, Wikipedia as a whole is less than 20GB in size, or 0.02TB. GPT-2, the predecessor, was trained on 40GB of text. So this latest version has swallowed up information from all over the internet. As a result, GPT-3 has experience about all kinds of things. Here is an example of converting difficult legal texts into simple English:
tb5lzwl3k2FnDjjD.mp4
With a few lines of Python and @sh_reya’s gpt-3 sandbox I got a demo web app up and running in less than 30 mins. What an incredible time to learn about software and be able to test things out so rapidly. pic.twitter.com/594ZUba885— Michael (@michaeltefula)
Generate code
Ok, so we’ve talked about generating text and converting difficult legal documents into simple English. GPT-3 is clearly a powerful model, but how does the language model perform in code generation?
In the meantime, several variations of GPT-3 are already available under different names for code generation. SourceAI, a paid API that is not yet available; GitHub Copilot, where you are the product; and OpenAI Codex, which will probably keep you on the waiting list forever.
SourceAI
SourceAI shows three use cases in a simple demo: translate, simplify and debug:
Codex
On the OpenAI website you will find a demo that shows how they create a space game with Codex in a few minutes, purely based on the code that is generated:
https://player.vimeo.com/video/583550498?h=90927a1846&dnt=1&app_id=122963
OpenAI goes one step further and demonstrates the various possibilities of Codex with an extensive live demo:
https://www.youtube.com/watch?v=SGUCcjHTmGY
Open source
Creating games and automatically generating code with language models is very cool, but none of the previous options are useful for the time being when you start working with production code. Each of these options relies on GPT-3, which is not openly accessible. The great news is that we can experiment even without GPT-3.
EleutherAI
Meet EleutherAI, a collective of researchers committed to keeping AI research open source.
Eleuther was initially known for The Pile, an 825GB dataset that is in turn a collection of 22 other high-quality datasets. The domains of this dataset are diverse, ranging from books, web pages and chat logs to medical texts, physics, mathematics, computer science and philosophy.
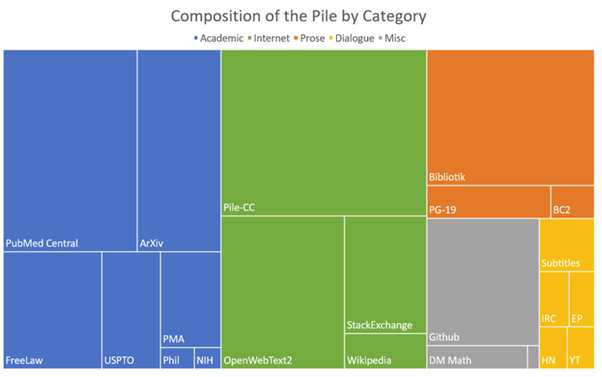
They have now also come up with a language model, baptized as GPT-J-6B, which is of course trained on their own dataset.
The intention of GPT-J-6B, which is not shy of anything, is to imitate OpenAI’s GPT models as closely as possible. You can find the pre-trained models on Hugging Face.
Here are some examples of what this model can do. I always came up with these myself, so feel free to play with them further. The bold text is always the input for the language model, he then builds on this and guesses what the sequel should look like. You can see that the structure is always beautifully copied and then supplemented.
Generating text
Here I started with something similar to the title of an article. The model supplemented this a little further and then started coming up with content that fits this title. Please note that this means that the model dares to say things that are grammatically correct, but in reality are not correct at all.

Legal Text
Here the vast majority of input is to help the model understand the structure of the desired outcome, and the most important information is therefore the first paragraph that follows. After this, a number of paragraphs followed, cut out from this screenshot, and the model himself started to come up with examples of legal clauses that he then converted into simple English. So pay attention to this when you want to parse the output of a language model.

Dialogue
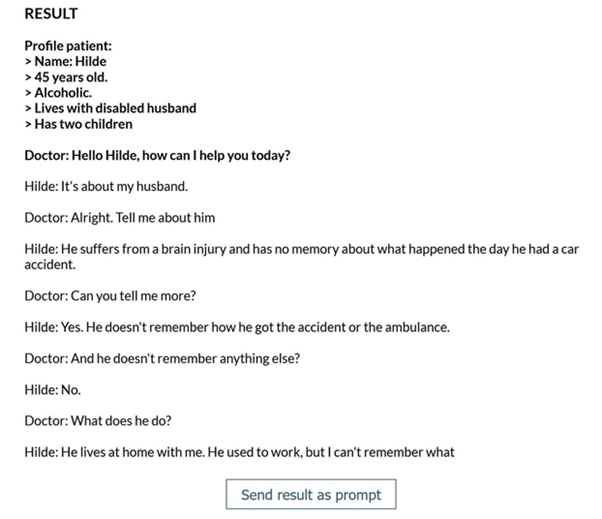
Code
And now we have arrived at automatic code generation. Those who have studied The Pile above will have noticed that GitHub and StackExchange make up a nice share of the dataset. Let’s see if the model can complement the class below in C#.

Even though this is obviously not the correct follow-up code, it is already a good sign to see that the brackets are closed and a variable is reused. The idea that other keypresses might be possible is also understood. Let’s compare it with the SQL example from SourceAI. In the following case I lowered the temperature (creativity) of the model a bit:
The model has not been given an example of what the structure of the answer should look like, which makes the challenge just a little more complicated. Once again there is too much text being spewed out here. Ultimately there will be an answer that is more or less correct, but just like GPT-3, both language models spontaneously assume that there is an ID column that must be set to 1.
Using the language model locally
Because the language model I have used so far is gigantic and cannot simply run locally on your system in two clicks, it has also been made available via your browser. This way everyone can test the capabilities of such a model. The following example is no longer via the web browser but a version that runs locally.
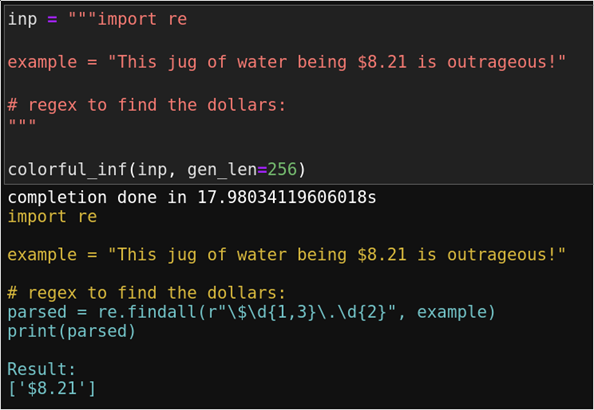
The result above is beautiful. The yellow text is input, and the blue text is the output code generated by the language model. Not only is the correct code generated here, a print statement is also added with the expected output of the generated code. All this without a compiler, of course.
GPyT
On Hugging Face there is a model called GPyT . This is a version of GPT-2 that has been trained from scratch on 80GB of Python code. Obviously this version will not outweigh Codex, but at least you can fully study this model and test it to its limits. The author warns against use in production, as the model could easily spit out harmful or copyrighted code.
Conclusion
It looks like language models that automatically generate code could eventually become part of everyday life for some programmers. However, at this point it is still a gimmick to use for research or personal projects. It remains to be seen to what extent the hype will catch on and be successful.
Since GPT-4 may be up to 500x larger than GPT-3, there is a real chance that major leaps in programming assistance will be made in the near future. EleutherAI is also not standing still and is busy releasing an open source and worthy alternative to GPT-3. These models will undoubtedly have more and more use cases for use in our daily lives.
