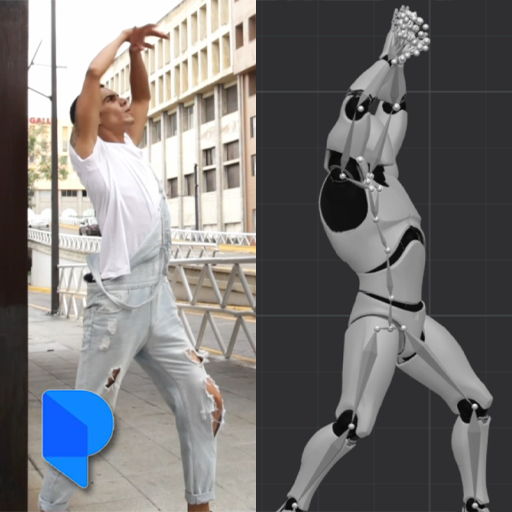
At the start of any project, it’s important to communicate ideas clearly. Creating visualizations is an effective way to convey concepts more precisely than words alone. This blog post explores various tools that help transform ideas into visuals....